Traversing a Directed Graph: Help for a JavaScript implementation of an algorithm for visiting each node in a directed graph only once, in an order derived from the graph.
Purpose of This Page
I have a problem. I've come up with a theoretical solution. Trouble is, I'm having trouble coming up with an elegant implementation of that solution in JavaScript, which is my ultimate goal.
Because it's difficult to ask for help without laying out the whole situation for inspection, this page exists to lay out the background of the problem, define the theoretical solution, and to solicit your help in creating an elegant implementation.
Background
While this problem is likely quite applicable in other circumstances, mine is specific--I'm implementing (or have implemented, depending on what you consider 'done mode' vs. 'optimization mode') a generic JavaScript library for setting up complex client-side calculations between elements on a page. Think 'Excel', but with custom HTML layout of the elements involved, referencing all elements by unique IDs rather than some grid system, and allowing circular references.
Because the results of one formula may affect another, in storing the formulae the library keeps track of which cells are dependent on each other. Whenever a cell's value changes, the formulae for all dependent cells must be re-evaluated (and whichever formulae are dependent upon those cells are updated...and so on and so on).
Circular references are allowed, although they only make sense if the formulae in the cells involved are mathematical rearrangements of one another (such as a=b*c, b=a/c) so that entries in any cell produce the same results in the others.
At certain times (when a page is loaded with some values from a DB, for example) it is necessary to run all the formulae on the page, to ensure that all results displayed are consistent with the formulae underlying them.
The Problem(s)
One problem, already solved, is that of detecting circular references and avoiding infinitely looping or recursing because of them. [The solution is to track the calling history along the way not not revisit any cells present in that history.]
The main problem is that of efficiency. Consider the following example set of relationships:
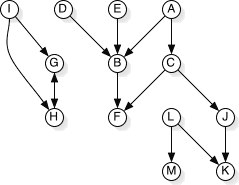
Each lettered node represents a formula.
A→B means that B depends upon A; a change to A should yield in the formula for B being run.
G and H are involved in a circular relationship.
If I go to update all the formulae on the page by traversing the nodes from A-Z, doing a depth-first update on the dependent nodes of each (but avoiding circular references), following is the order the nodes are visited:
A B F C F J K | B F | C F J K | D B F | E B F | F | G H | H G | I G H H G | J K | K | L K M | M |
Horrific! The 'F' node gets evaluated 7 times! The 'H' node gets evaluated 4 times! Altogether, 20 nodes are evaluated, when only 12 needed to be run. Terrible! (The same problem, although to a lesser extent, is possible when updating any single node, as seen in traversing the update tree for the 'A' node.)
Obviously if 'B' is going to be evaluated as a result of updating 'E', there's no reason to evaluate it any earlier. (If it's not obvious, trust me--it is so. And understand that I'm glossing over a non-solution I mistakenly made earlier, where I update B the first time, and then no later.)
The Solution (conceptual)
In general, the system needs to look ahead and only actually run the formula for each node the last time it's going to be visited. This can be done by traversing the dependency tree first (avoiding circular references) and building a list of the nodes to run, and then removing all the duplicates from that list, leaving only the last instances of each.
In the example above, the initial traversal yields a node visitation order of:
ABFCFJKBFCFJKDBFEBFFGHHGIGHHGJKKLKMM
Removing the duplicate items (and keeping the last occurance) gives:
ABFCFJKBFCFJKDBFEBFFGHHGIGHHGJKKLKMM
Or simply:
ACDEBFHIGJLKM
The JavaScript Implementation
Here's where I need your help. I have no trouble actually implementing a solution, but all of mine seem overly cumbersome. Here's an example implementation, in pseudo-code:
- Traverse (without evaluating) the dependency tree, shoving each node's string into an auto-growing Array.
- Iterate through that Array in reverse order. At each stop, shove the string into a hash (Object) if it doesn't already exist there. If it does exist (already been seen along the way) set the Array spot to null.
- Run through the array again in forward order, skipping the empty holes where duplicates were removed, and actually running the formula for each existing node along the way.
The overhead of this solution might be worth it when doing the global update of all formulae on the page, but for simple updates (e.g. if J changes) this seems like it would slow the overall system down if used for every update.
Another thought I had involved keeping a running counter while running through the hierarchy the first time, and shoving that value into a hash table keyed on the node's string. Doing this would ensure that each node in the hash existed only once, and had a priority number which could be used to sort the nodes for traversal. Except, oh yeah, I'd need to then iterate over the keys in the hash and shove them into an Array's indexed positions in order to be able to sort them. Hrm...
So...what's the cleanest/fastest JS implementation you can come up with to do this?
Update: Four implementations have beed developed so far:
- Double Loop
-
This is the implementation I outlined above, and although testing is incomplete, it seems to be tied for first place, if not the best all-around performer! Very surprising.
Overview: (see above)
Sample Code:
out=[]; seenIt = {}; for (var i=0, len=inputs.length;i<len;i++) out[i] = inputs[i]; for (var i=out.length-1;i>=0;i--){ var thisOne = out[i]; if (seenIt[thisOne]) out[i]=null; seenIt[thisOne]=true; } for (var i=0, len=out.length;i<len;i++) if (out[i]!=null){ //run the formula } - Loop w/Hash
-
This is similar to the above, but removes the duplicates on the fly in the initial loop. Despite this optimization, performance is sometimes slower than the Double Loop implementation, sometimes faster.
Overview:
While receiving the input strings, stick them into an auto-growing Array. Use a Hash table to store the last-seen index of each and, when a duplicate is added, set the previous entry in the Array to null.
Sample Code:
out = []; previousPosition = {}; for (var i=0, len=inputs.length;i<len;i++){ var curKey=inputs[i]; if (previousPosition[curKey]!=null) out[previousPosition[curKey]]=null; previousPosition[curKey]=out.length; out[out.length]=curKey; } for (var i=0, len=out.length;i<len;i++) if (out[i]!=null){ //run the formula } - Hash and Sort
-
This implementation is far more efficient than the previous two...as long as the cleanup ratio is high; that is to say, if 90% of the input items are duplicates, this implementation does very well indeed. Below something like 70% duplicates, however, this implementation takes a nose dive. Again, solid performance numbers are still in progress, but it looks like it's 3-5 times slower than the other methods at something like 20% duplicates.
Overview:
On initial traversal, use a Hash to store the last-seen index of each item. Afterwards, iterate the Hash and stuff those values into an Array, and then call the built-in .sort() method on the Array (which I believe uses QuickSort), passing it a custom comparison function for proper sorting.
Sample Code:
out = []; keyOrder = {}; for (var i=0, len=inputs.length;i<len;i++) keyOrder[inputs[i]] = i; for (curKey in keyOrder) out[out.length] = {key:curKey, val:keyOrder[curKey]}; out.sort(function(a,b){ return a.val>b.val?1:(a.val<b.val?-1:0) }); for (var i=0, len=out.length;i<len;i++){ //run the formula } - String Manipulation
-
Boy, what a mistake this one was. It's performance is flat-out awful, and gets worse the larger the input set. It's shown here only as an example of a BAD idea.
Overview:
Keep a space-delimited string representing the final output. As each input string is received, use String.replace() to remove it from the output, and then use += to concatenate it on the end.
Sample Code:
out=""; for (var i=0, len=inputs.length;i<len;i++){ curKey=inputs[i]; //surrounding spaces needed to prevent replacing partial words out = out.replace(" "+curKey+" "," "); //extra space needed at end because space needed above, and using only //one would prevent finding word at either beginning or end of list out+=" "+curKey+" "; } out = out.split(" "); for (var i=0, len=out.length;i<len;i++){ //run the formula }
|
Gavin Kistner
11:06PM ET 2001-Nov-30 |
Another thought I just had: rather than shoving them in an Array originally, keep a space-delimited string, and use .replace() to trash the value if it already exists before using += to append it to the end. Then use .split to get a list of nodes to traverse. Hrm, that might not be so bad... |
|
Gavin Kistner
05:12PM ET 2001-Dec-01 |
As an interim update, the string method turns out to be at BEST 2x slower than the double-loop method above, and as the dataset grows so does it, where I've seen it be 10x slower in some tests. (I believe this is because I was (unecessarily) doing a global replace, which in JS requires a regexp object.) There is a new, slightly faster method which was created with the help of 'neatsun' on #javascript (irc, EFNet). I'll update this page with the actual algorithms described later, but for now you can see the test and performance numbers. |
|
Gavin Kistner
05:25PM ET 2001-Dec-01 |
Just tried it without doing the global replace (because there should never be an item in the output more than once) but with a straight-up string replace instead. Still almost 2x as slow. |
|
Thayer York
02:05AM ET 2001-Dec-03 |
I like your idea when it comes to a global update (many of the items have been changed). But I agree it's too much work when doing a simple one. My thoughts tend towards taking an alternate, optimzed approach to simple updates. BTW - every time I encounter something like this I can almost hear one of my old CSci professors talking about the "space/time" tradeoff - if you want it to run faster, throw more memory at it. Thought #1
Then, when a simple update occurs, look up the appropriate sequence and go for it. This could be extended to dual and triple node updates, but the storage requirements quickly get out of hand. For multiple node changes you may also be able to retrieve the relevant cached update sequences and combine them to yield the single sequence of updates required. Thought #2 |