Modeling Web Applications with UML

jim conallen,
Principal Consultant
jim@conallen.com
Last Updated: 9-Mar-1999
Introduction
Web applications are becoming more and more popular. This is in part due to the rapid deployment of the tools and technologies for developing them. But mostly because system designers are recognizing the situations where web applications have very significant advantages over traditional applications.
To date the focus of web application development has been the tools. Little attention has been paid to the development process. Current development environments make it so easy to produce simple web applications that they have the unfortunate side effect of encouraging us to develop and evolve applications in the absence of serious analysis and design. Any system with non-trivial complexity needs to be designed and modeled. A primary goal of this paper is to stress the need for proper modeling. Unfortunately modeling web applications is not obvious.
Most of my experience with web applications comes from my use of Microsoft’s Active Server Page technology. I have made a very strong attempt to make the discussions in this paper as generic as possible, so that other technologies such as Allaire’s Cold Fusion could also be used. In addition web applications based on CGI scripts or ISAPI filters can still benefit from the modeling techniques described here.
This paper begins with a very brief explanation of web architecture. To keep it short, discussions of images, image maps and other primarily user interface features of web sites and applications have been omitted. The focus is on the ability of a web application to function as a software application, and the details of display and formatting are only of interest in those special cases where they directly effect the business logic. Also not addressed is use of external applications and MIME types.
Discussions in this paper assume working knowledge of UML, and some knowledge of web applications. The audience of this paper are developers and designers of web applications, and it is assumed that they are familiar with their own web application development environments.
Web Application Architecture
Web Sites
There is a subtle distinction between a web application and a web site. For the purpose of this paper a web application is a web site where user input (navigation through the site and data entry) effects the state of the business (beyond of course access logs and hit counters). In essence a web application uses a web site as the front end to a more typical application.
The architecture for a web site is rather straight forward. It contains three principal components; a web server, a network connection and one or more client browsers. The web server distributes pages of formatted information to clients that request it. The request is made over a network connection and uses the HTTP protocol. Figure 1 shows this relationship. Some web sites require clients to logon, and some allow anonymous access.
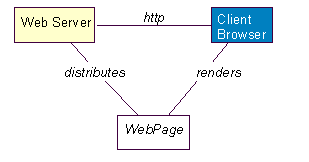
Figure 1 Basic Web Application Architecture
The information made available by a web site is typically stored, already formatted, in files. Clients request files by name, and when necessary provide specific path information with the request. These files are termed pages, and represent the content of a web site.
In some situations the content of a page is not necessarily stored inside the file. It can be assembled at runtime from information stored in a database (or other information repository) and formatting instructions in a file. Alternatively it can come from the output of a load-able module (CGI or ISAPI). The web server uses a page filter to interpret and execute the scripts in the page. Web sites employing this strategy are called dynamic sites.
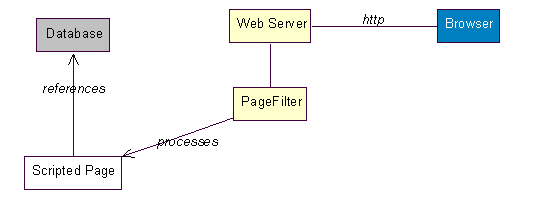
Figure 2 Dynamic Web Site Architecture
Dynamic web sites offer certain advantages to web site designers. They make it easy to keep the content fresh and synchronized with data in a database. The overall look and feel of the web site is defined by a set of pages that contain code executed by the web server during a request for this page. In this context the file can either be an plain text file with scripts interpreted by the web server, or a compiled binary file that is executed by the web server. In either case the code in the "page" references and utilizes server resources which include databases, email services, file services, etc.
A user interacts with a web site via a browser. A browser is an application that runs on a client machine, that connects to a server on a network and requests a page of information. Once the page request has been fulfilled the connection terminates. The browser knows how to communicate (via HTTP) to a web server, and how to render formatted information returned by the web server. Most pages of information contain links to other pages (possibly on other servers), which the browser user may easily request. Users navigate the web by clicking on links and requesting pages from web servers.
Web Applications
The distinction between web sites and web applications is subtle, and relies on the ability of a user to effect the state of the business logic on the server. Certainly if no business logic exists on a server, the system should not be termed a web application. For those systems where the web server (or an application server that uses a web server for user input) allows business logic to be effected via web browsers, the system is considered a web application. For all but the simplest web applications the user needs to impart more than just navigational request information, typically web application users enter a varied range of input data. This data might be simple text, check box selections, or even binary and file information.
The distinction becomes even more subtle in the case of search engines, where users do enter in relatively sophisticated search criteria. Search engines that are web sites, simply accept this information, use it in some form of database SELECT statement and return the results. When the user finishes using the system there is no noticeable change in the state of the search engine (except of course in the usage logs and hit counters). This is contrasted with web applications that, for example accept on-line registration information. A web site that accepts course registration information from a user has a different state when the user finishes using the application.
The overall architecture of a web application is identical to that of a web site. It can however, become significantly more elaborate. The rest of this section will attempt to gradually build on the web site architecture to eventually reach that of a fairly complete and complex one. Given the history of this industry, this classification of fairly complete may not even last by the time this paper is completed. Regardless it will contain most of the concepts and components that are expected to be the cornerstones of web applications for the next several years.
Pages
By far the most fundamental component of a web application is the page. Browsers request pages (or conceptual pages) from servers. Web servers distribute pages of information to browsers. The makeup and organization of a web pages in essence make up the user interface for the application. In web applications the browser acts as a generalized user interface container with specific user interfaces being defined by each page’s content.
In web application development environments like Microsoft’s Active Server Pages or Allaire’s Cold Fusion, the pages are a combination of static HTML formatted pages, and dynamic scripted pages. The scripted pages contain code that is executed by the web server (actually it is more likely to be delegated to a scripting engine or page filter) that accesses server resources to ultimately build an HTML formatted page. The newly formatted page is sent back to the browser that requested it.
Server Scripting
It is important to note that the connection between the client and server only exists during a page request. Once the request is fulfilled the connection is broken. All activity on the server (as effected by the user) occurs during the page request. This represents a very significant distinction between traditional client server applications. Business logic on the server is only activated by the execution of scripts inside the pages requested by the browser.
Depending upon the specific scripting engine, scripted pages can contain user defined variables, sub routines and functions. Some scripting engines even permit the definition and interaction of objects.
The ultimate result of this server processing is to;
An important and subtle part of web application design is understand and accommodating of this paradigm of client and server interaction. Business objects are not always accessible when handling individual user interface requests. For example a common user interface (and business feature) in many client server applications is the automatic population of city and state fields in a US postal address when a zip code is entered. Assuming that all three fields are located on the same page in a browser this feature would require an additional server page request to happen immediately after the zip code was entered. For most web applications this carries with it an unacceptable performance burden. For most web applications page requests are fulfilled in an order of seconds instead of milliseconds.
Client Scripting
The server is not the only component in a web application that executes scripts. The browser itself can execute scripted code in a page. When the browser executes a script, however, it does not have direct access to server resources. Typically scripts running on the client augment the user interface as opposed to defining and implementing core business logic.
Scripts on the client are appropriate for immediate data validation, or in assisting navigation. Often client scripts simply "jazz" up the user interface and provide little if any business logic behavior. This is changing however, as client side scripting becomes more powerful, and client side resource become more a part of the overall application.
Client scripts should not be confused with client side components such as Java Applets or ActiveX controls. These components are a separate category of component in the overall web application architecture and are discussed in more detail later. The client scripts discussed here are JavaScript (or VBScript) code embedded in the HTML formatted page. The code is executed in response to browser generated events (document loaded, button pressed, etc.). With the acceptance of the new Dynamic HTML specification, client scripts can access and control nearly every aspect of the page’s content. Additionally it further opens up access to the browser object model itself, enabling client side scripts to interact with other browser resources.
When an HTML web page is rendered in a browser it is first parsed and divided up into elements. When dynamic HTML is employed each of the elements can be named or assigned an ID, which could be referenced by client side scripts. Some common element types include anchors (links to other pages), tables, font specifications, etc. The elements making up the content of the page have an object interface defined by the Document Object Model (http://www.w3.org/DOM/). The browser also has an accessible interface, yet differing brands of browsers may have subtle differences.
Client scripts, like their server side counterparts, may contain variable declarations, sub routines and functions. The only major conceptual difference is server side scripts contained in a page are inherently procedural, while client side scripts are inherently event driven.
Forms
Any serious web application accepts more than navigation input from its users. Web applications often illicit textual, selectable and Boolean information. The most common mechanism for collecting this type of user input is with HTML forms.
An HTML form is a collection of input fields that are rendered in a web page. The basic input elements are; a textbox, text area, checkbox, radio button group, and selection list.
All the input elements on a form are identified by name or ID. Each form is associated with an action page. This action page represents the name (and location) of the page that is to receive and process the information contained in the completed form. The action page is almost always a dynamic page, containing server side scripts (or compiled code).
When a form is completed by a user the user submits the form back to the server with a page request for the action page. The web server finds the page and interprets (or executes) the page’s code. The code in the page has the ability to access any information in the form that was submitted with the request. This is the major mechanism for obtaining user input in a web application.
Components
Server
All business logic needn’t be interpreted from scripts in web pages. Larger and more enterprise savvy web applications make use of a third middle tier of components. This middle tier exist in between the user interface and the persistence system, and is typically a set of compiled components that run on an application server. The application server may execute on the same machine as the web server but does not necessarily have to. One of the advantages of an explicit third tier running on a server is the ability to share implementations of business functions across applications, web or not. Another is an encapsulation layer, for all business logic. A full description of the merits of three tiered architecture is beyond the scope of this paper.
When a compiled middle tier of business objects is present in the architecture the server scripts in the web pages, primarily act as the glue between the user interface and the business layer. Scripts executed on behalf of the web server have references to business objects, creating and invoking methods on them. It should be noted that as before, server side business logic is only executed on behalf of the user during page requests. The processing of a page request may result in a process or two to get executed on the server, and remain executing long after the client browser has shut down, but the process would be running in isolation from the client. Even when compiled business object components are used, the connection between the client and the server is closed once the requested page has been received by the browser.
The correct decision to use a third tier or not is dependent upon the specific application. Some points to consider include improved performance time with compiled business objects. Interpreted scripts execute slower than compiled code, and when performance is important, should be kept to a minimum. An advantage of server scripted business logic, however, is an easier ability to modify or enhance code, without taking down the application. Changes can be made to server scripted pages (within reason) without stopping the application. If the amount of business logic is relatively small, the absence of a full middle can be very appropriate.
Client
HTML formatted web pages may also specify components for execution on the client machine. The most common of these components are Java Applets, and ActiveX controls. Each are self contained compiled components that run at the request of the browser. Depending upon browser and component configuration they have access to browser and/or client machine resources.
Components on the client raise significant security concerns which are better addressed outside this paper. It should be sufficient to say that compiled components executing in the browser and on the client can make up a significant part of a web application’s architecture.
Client components are very useful in providing user interface functionality not readily achievable with standard form or HTML elements. A client component might be a display control that visualizes a three dimensional model. It might also represent a user interface control to specify dates with, one that pops up a miniature calendar from which dates can be clicked on. Some client components have no visual display, and might be used to retrieve client machine configuration information (a very touchy subject with the Internet community).
Frames
The user interface capabilities on the client can be enhanced with the use of frames. Frames and the ability to target browsers, enable the user interface designer to have multiple web pages active and open at the same time. The browser divides up its rectangular client window (where web pages are rendered) into distinct frames (or sub rectangles). Any web page can specify a frameset, and it is possible for a frameset to be embedded inside other framesets.
Scripts and components in any of these pages can interact with scripts and content in others. In HTML this is all managed by associating a target with each frame in a browser window. A proper discussion of the use of frames in user interface design is beyond the scope of these discussions, however the point must be made that the use of frames does constitute a major design decision in a web application, as it indicates that multiple pages are simultaneously available to the user.
Figure 3. shows a summary of the major architectural components discussed here. Two additional components; Application Dictionary and Session Dictionary were influenced by Microsoft’s implementation of Active Server Pages and offer a convenient mechanism to manage client side state on the server.
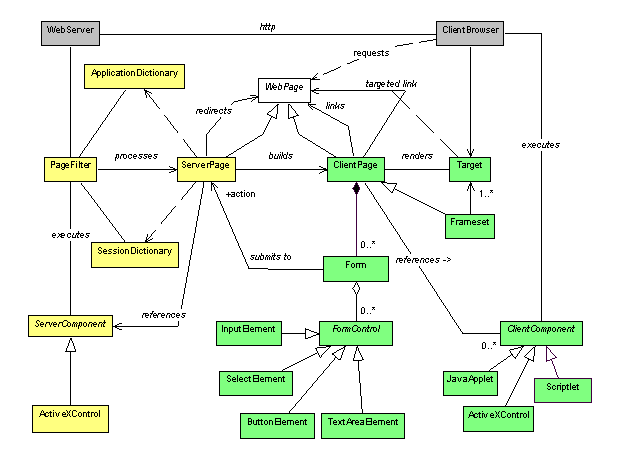
Figure 3 Model of a generalized web application architecture
Other Components
A very effective and complex web application can be developed with the components mentioned previously. But nothing is good enough when technology is concerned. Some of the latest developments in the web application area still impact the architecture. Included in this are scriptlets and XML. Scriptlets are presently a Microsoft browser exclusive and therefore only an option when it can be guaranteed that all clients are using Internet Explorer 4.0 or later. The other, XML is also pushed by Microsoft, but is receiving an unusual amount of independent support.
A scriplet is a cached HTML page (with possible object references) on the client that is used by many pages in a web application. The obvious advantages are re-usability and lowered network traffic.
XML (eXtensible Markup Language) is subset of SGML (Standard Generalized Markup Language) and defines how related data can be transmitted across the web in a standardized way. Much like how HTML uses tags to describe the formatting in a web page, XML enables user defined tags to describe the meta-structure of data with the actual instance data as it is transmitted between server and client. Again this is not the proper place to discuss in detail XML, the most recent draft of the XML standard can be found on: http://www.w3.org/pub/WWW/TR/WD-xml.html. For the purposes of this paper XML defines a portable way to encode hierarchical data.
Modeling
Modeling is important. It helps us manage complexity. Web applications can get complex rather quickly. A given system can be represented by many different, yet consistent models. Each model has a specific purpose and audience. This paper focuses on design models for web applications, and the audience is primarily the web architect and designer. It is important when modeling to capture the appropriate level of abstraction and to model the artifacts.
With these goals in mind the task of modeling web application design becomes not so clear. Given the assumption that the primary artifact of a web application is the web page, it should be obvious that the page should be modeled. But how? Using UML we can express a page as an object. This then brings up the question; what are the properties of such an object? Is it appropriate to express the layout elements (fonts, tables, text, etc.)? Should the scripts in a page be identified as methods of a page object?
The answer should come from the question; what is the model being used for, and who is the audience? In the case of a design model, the user interface formatting is irrelevant, and typically doesn’t effect the business logic in the system. Scripts, especially server side scripts, do effect the business behavior of the system (and in some systems represent the entirety of the system’s business logic!). Additionally it is not hard to visualize variables in a scripted page (those with page scope) as being attributes of a page object and the function in the page as being its methods. These are appropriate for a design model and for a web application designer.
This however, leads to another problem. Web pages can contain scripts for both the server machine as well as the client. Intermixing attributes and methods for server and client execution can be very confusing. Solving this problem involves using a relatively new feature in the modeling toolbox; extensions.
Modeling Extension
The designer’s of UML recognized that the language is not always perfect for every situation. There are times when the development process would be better served if additional information we captured, or different semantics were applied to certain modeling elements. UML has defined a mechanism to allow certain domains to extend the semantics of specific model elements. The extension mechanism allows the inclusion of new attributes, different semantics and additional constraints. When collected together as Tagged Values, Stereotypes and Constraints they form an Extension to UML. This paper presents an extension of UML for web application designs.
Part of the extension mechanism of UML is the ability to assign different icons to stereotyped classes. A list of prototype icons for the most common class stereotypes can be found as an appendix to this paper.
The problem of a web page having different scripts and variables executed on the server or on the client can be solved in one of two ways. The first would be to define the stereotypes; server method and client method. In a page object a method that executes on the server will be stereotyped as «server method» and functions that run on the client «client method». This solves the problem of distinguishing attributes and methods of a page object, however it is still confusing. A further complication arises later when associations are made to other components in the model. It is not clear that some of these relationships are valid only in the context of the server methods and attributes or on the client.
Page Stereotypes
A better way to model a page is with two separately stereotyped classes; server page and client page. Any given web page in a web application that has functionality on the server as well as client can be represented in the model as two separate classes, even though their implementation is in the same file (or component). In this situation a web page’s server methods and page scoped variables are all contained in a class in the model stereotyped «server page». This class’s methods represent the page’s server side script’s; sub routines and functions. Variables declared in the scripts that have page scope represents the class’s attributes. Client side scripts or user interface formatting are not part of a server page’s scope. A server page can have relationship’s to components that exist on the server. These might include the business objects in three tiered system’s or data access components. Components relative to the application’s design and operation on the server are represented side by side with the server page’s that use them.
Client pages are similarly represented on the diagram with classes stereotyped: «client page». Client page’s attributes are page scoped variables and functions that execute in the client browser. Client pages are associated with components that execute on the client, including Java Applets, ActiveX controls, and elements of the Document Object Model itself.
There is a fundamental relationship between the server and client stereotypes of a web page. A server page ultimately builds the resulting client page. This is a unidirectional relationship, since a completed HTML page has little access to the object interface of the building server page. The stereotype «builds» is applied to associations and is always drawn in the model as a unidirectional association from a server page to a client page (Figure 4.). It indicates which server page is responsible for building a given client page.
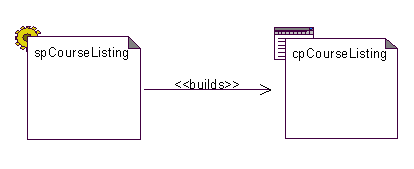
Figure 4 Server pages build client pages
It is conceivable that a given server page might build two distinctly different client pages. So different in fact, that it would be better (clearer) to represent the result as two separate client pages in the model. The merits of such design decisions may be debated, however, the extension mechanism doesn’t prevent such constructs.
Another facility of some web application development technologies is the ability to redirect the processing requests to another «server page». This relationship can be expressed in the model with the «redirects» association stereotype. A design might identify a particular server page a gatekeeper page, that given certain input, redirects further processing (and consequently different returning user interfaces). Redirection is a very useful feature for re-use especially in non three tiered web applications. Figure 5 shows this relationship.
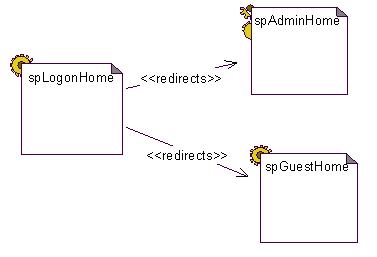
Figure 5 Server pages can delegate
A fundamental and yet subtle relationship between client pages and server pages is in the implementation diagram. Components in the implementation diagram represent distributable pieces of the system. For these stereotypes it is the web page. A component in an implementation diagram (component view in Rational Rose) represents an actual file that is request-able by the web server, and which realizes at least one server page or client page. Figure 6. conceptually shows this relationship.
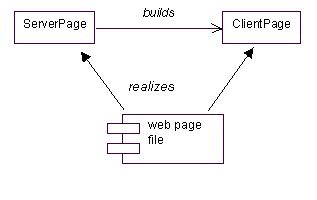
Figure 6 A web page components realizes both server and client pages
An additional relationship that may be of importance in web application design is the hyper link. Client pages often contain hyper links (anchors) to other web pages. These other web pages can be either server or client pages, since ultimately it is the component that is requested by the client browser. If the requested component realizes a server page (at most one) then the server page is processed in order to get a resulting client page to fulfill the browser’s request. If not the web server simply retrieves the requested component (file) and sends it back to the browser.
The stereotype: «links» is defined for associations between client pages and other pages (server or client). See Figure 7. The decision to model all the hyper links in client pages is really left to the designer, however, a good design should model all relevant hyper links to the functioning of the application. It may not be necessary to model hyperlinks to web pages outside the system, or to company home pages and the like. A «links» association may be a bi-directional association. A «links » relationship from a server page does not make sense. If the hyper link includes parameters, they are be modeled as link attributes off of the association, as shown in Figure 8.
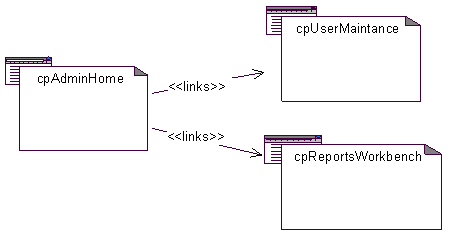
Figure 7 Client pages can like to each other
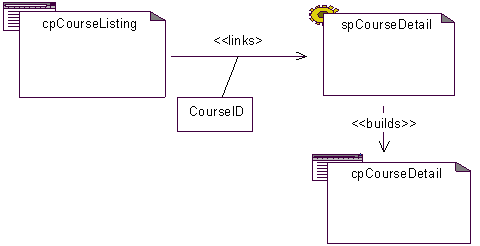
Figure 8 Linking with parameters
Components
Components in the sense of interfaces available to objects in the web application like ActiveX controls and DLLs, Java Applets or executables are also given a stereotype in the web extension. Just with pages components are identified as being executed on the server machine or on the client machine. The stereotype’s «server component» and «client component» can be applied to classes in the design model to distinguish availability. Certainty a database access component on the server is not directly accessible by client scripts running in a browser. Stereotyping components (interfaces) in the design model helps to clarify the model.
Forms
Additional stereotypes are defined for separating and elaborating HTML Form usage. Forms in an HTML formatted page really represent a distinct part of the client page. Forms contain additional attributes that may not be appropriate in the context of the entire client page. It is also possible to have multiple forms in a single page, each targeting a different action page. This can be modeled by creating a new stereotyped class to represent a single HTML form; «form».
A form class has as attributes is field elements. Methods however do not apply to forms, as a method defines a dynamic behavior within the context of a single form. Methods in a client page have access to all attributes of forms contained within a page. The proper relationship between a client page and a form is containment. Client pages contain forms.
A form identifies a specific web page (almost always one with a server page stereotype) to accept and process data submitted with the form. A «submits» association stereotype represents the relationship between a form and the web page that processes it, see Figure 9. The association is bi-directional since the processing page has access to the form’s attributes, which are submitted when the association is realized during runtime.
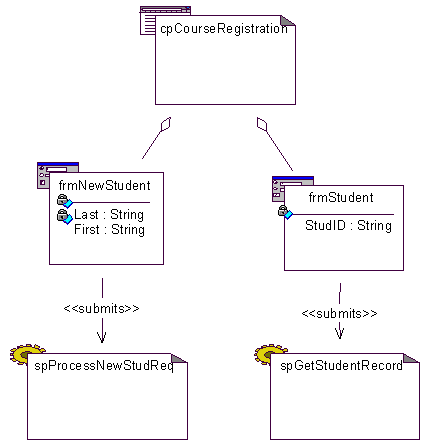
Figure 9 Forms submit to server pages
Framesets
An additional user interface (and design element) available in web applications is the frame. If used in an application, it represents an ability to present multiple web pages at the same time. Typically these concurrent pages which are related together to represent a single user interface.
Frames are implemented in HTML by defining a frameset. A frameset specifies and optionally names separate frames in which web pages can be rendered. The implementation of a frameset is in an HTML page. To maintain compatibility with older non-frames capable browsers, a frameset web page usually contains formatting and informational content that is only seen on the older browsers. This leads us to model framesets as a client page, but a specialized one, and hence a new stereotype: «frameset». In a design model classes stereotyped frameset may have all the associations that a client page can have, with the understanding that these are only appropriate for older browsers.
More typically, framesets contain multiple client pages. Any client page can be contained by a frameset. Since a frameset is just a specialization of a client page, it too can be contained in a frameset!
Coordinating activity between pages in frames (or other windows) requires the ability to reference pages inside of frames. Target is the term used when a client page references another active web page or frame. Since targets represent a very different element from a frameset, and considering web pages can also reference targets that are in other opened browsers, another class stereotype is defined; «target». A target has no properties or attributes, it is merely a reference-able container for a client page. A frameset class can contain a target, or a target can exist independently (as in the case of a separate browser window).
The main advantage of pulling out target as a stereotype is that it can be shared and referenced by many client pages. Additionally since it has no meaningful attributes or methods its semantics are different from normal classes.
A final stereotype needs to be defined for associations that indicate that one client page is requesting a link to be loaded into a browser window other than itself. A «targeted link» stereotype is applied to associations between client pages and targets that they interact with. Parameters that are passed to the server with the targeted link can be identified with a UML link attribute. See Figure 10.

Figure 10 Using framesets and targets
Other Stereotypes
At the present time the web extensions for UML are just being finalized for their initial release. Under consideration are the following class stereotypes;
| «scriplet» | A scriplet is a cached client page, that typically contains references to components and controls that are re-used by subsequent client pages. Its primary significance in the design model is that it is an available source of re-use for client pages. |
| «xml» | An XML stereotyped class represents a
hierarchical data object that can be passed to and from a web server and client browser.
XML is a standard way to represent hierarchical data in an application independent way. Uses and tools for XML are just now emerging, and it expected that XML will play a larger role in web applications. |
One user interface feature of a web application not addressed yet is the ability of a client page to pop up a modal dialog box, to gather user input. Client scripts invoke this operation, and this is modeled with a directional association from a calling client page to another web page (server or client). The association is stereotyped «dialog», indicating that the client page calling the dialog is temporarily suspended until the called "dialog" page closes. Typically a client page calls a dialog page to get small amounts of user input that either don’t fit on the original client page or is so infrequently used that it isn’t worth the screen real estate to put there.
The last stereotype under consideration is «event» and is the only method stereotype of the extension. It applies to methods in a client page object that are handlers to browser generated events. These help the designer to visualize which behaviors in a client page can happen asynchronously.
Process Considerations
Knowing the semantics of design models is certainly only part of the process of delivering quality software. Before concluding our discussions on modeling web application design I would like to offer a few words of advice regarding the steps to take when developing web application designs.
A web application is a specialized version of a client/server application. Many of the development activities appropriate for client/server application development also apply to web applications. The importance of requirements modeling can not be emphasized enough. Use Cases provide an excellent way to capture and model a systems requirements. Although not all requirements are present in use cases, they do provide an excellent mechanism for organizing specific functionality and especially user interaction.
A use case is a textual description of the interaction of the system and the user, in the language of the domain. How tightly coupled use cases are with user interfaces is yet another matter of great debate. It should be sufficient to say that an examination of a system’s use cases provides an excellent starting point to identify client pages in the application. For the first iteration of design it is a good idea to start off with one client page for each use case involving interaction between a human actor and the system.
Do not attempt to model server pages yet. Especially in three tiered systems, server pages are only the glue between client pages and server components. The next step is to model the business objects of the system. With the business objects modeled and the client pages identified, begin gluing them together with server pages. Most likely there will be one server page for each client page that contains business object data.
Like any realistic project there will be several rounds of iteration and possibly significant changes in the design. Using the extension presented earlier will help present to the designer and implementer a clearer picture of the actual web application design.
Conclusion
The major purpose of this paper is to present a mechanism to assist web application designers. With the assumptions that modeling is important, and we should modeling the artifacts of a system, it becomes obvious that web application designers must work with pages. Since UML is fundamentally object oriented, and web pages are inherently not a disconnect arises. The solution, as presented here, is to apply some new semantics to special model elements, to help bring out their hidden object oriented aspects.
As a final note, it has to be mentioned that the extensions presented here are still in development. For the most part they have been driven my recent experience developing web applications with the Microsoft set of technologies. Its hoped that the user community will help refine the extension and additional processes such that in the near future it can considered a reliable tool in the creation of web applications.
Comments and suggestions are very welcome and can be sent to jim@conallen.com.
Appendix A. Stereotype Icons
| Class Stereotype | Icon |
| Server Page |
|
| Client Page |
|
| Form |
|
| Frameset |
|
Target |
|
Copyright 1998-1999 jim conallen, Conallen, Inc.
jim@conallen.com